
Blueprints for a Data Analytics Platform by Ranjan Bhattacharya
Introduction
In a previous article on the Modern Data Architecture we have talked how the data analytics architecture has evolved over time, from the traditional on-prem, data warehouse implementations to modern cloud-based footprints. Organizations migrating to the cloud can access and use data in ways that were unthinkable with traditional on-prem models.
This paper expands on those topics, covering the architecture, the tools, and the benefits and challenges of each of these implementation blueprints.
On-Prem Analytics
The Enterprise Data Warehouse
A traditional analytics architecture consists of a data warehouse, ingesting data from multiple operational data stores through ETL processes, and fronted by BI and reporting tools.

The benefits of this architecture are several:
It is composed from well-understood architectural patterns and tools.
There is a wide availability of skilled practitioners.
It can satisfy quality requirements like data integrity, consistency, performance, and availability.
For an organization dealing with relatively slow-moving structured data of moderate volume, this architecture may well be able to satisfy its analytical needs.
Some of the popular solutions in this space include:
Data Warehouse products from Teradata, IBM Netezza, and Oracle Data Warehouse.
ETL Tools: Informatica, Oracle Data Integrator, and Talend Data Fabric.
However, the enterprise data warehouse architecture suffers from several challenges:
Scaling on-prem software products requires over-provisioning hardware to handle peak load. There is no way to dynamically scale up or down based on demands.
Data can get stale or incomplete between scheduled runs of ETL processes.
Queries on large datasets can be slow.
History and lineage information of the data typically is not preserved.
There is limited support for storing and searching non-structured data or for ingesting streaming data.
There is limited support for integration with external tools and analytical engines.
Development of dashboards and reports needs technical expertise leading to long lead times to fulfill requests from business users.
Expensive to license, build and maintain, requiring regular updates, and performance tuning.
The Enterprise Data Lake
The next evolution of the on-prem architecture incorporates two key innovations—the data lake, and the ELT workflow.
The data lake stores raw data from diverse sources—real-time, and streaming, and formats—structured, unstructured, and binary—preserving history and lineage information. Also, analytical tools can process data directly from the lake without needing it to be moved to the warehouse first.
The ELT (Extract-Load-Transform) is a variation on the ETL approach. As part of the EL (Extract and Load) stage, data is copied from different source systems to the data lake. In the T (Transform) stage, the data is cleaned, enriched, and moved to the warehouse or to other storage systems.

Most of the commercially available data warehouse products listed earlier have now expanded their capabilities to include data lake features. Another popular option is to build the data lake on open-source ecosystems like Apache Hadoop for storage and Apache Spark for transformation.
While a good step forward in handling large variety of data, and running analytics, the data lake footprint has its own set of challenges:
Reading and writing into data lakes can often lead to inconsistencies for readers while data is getting written unless steps are taken to address them.
Storing unstructured data into the lake without any validation of the schema or the contents can lead to poor data quality, turning data lakes into “data swamps!”
More data in the lake can lead to poor performance of ingestion and query operations.
Modifying, updating, or deleting records in data lakes is hard, requiring development of complicated data update pipelines, which are difficult to maintain.
Automation is implemented through a plethora of different tools and scripts requiring continuous troubleshooting and maintenance.
Cloud-based Analytics
The explosion of cloud-based tools has fundamentally changed the analytics architecture. The primary advantages of moving the analytics infrastructure to the cloud are:
Separation of concerns between compute and storage which can be independently provisioned and scaled.
It is easy and inexpensive to experiment and innovate without requiring a long evaluation and build phase of an on-prem installation.
Wide variety of cloud services, storage options, and integration mechanisms make it easy to ingest new data sources.
Cloud Lift & Shift
One option of moving to the cloud is to essentially do a lift and shift of the analytics infrastructure to the cloud. This option has the following advantages:
It offers a relatively simple migration path without extensive re-architecture.
It enables on-demand scalability, controlling cost.
It expands the storage and ingestions options for unstructured data.
Many of the data warehouse vendors listed earlier offer cloud-based migration paths for on-prem services. In addition, all the public cloud vendors have their data warehouse offerings as well: AWS Redshift, Azure SQL DW, Google Big Query, and Oracle Cloud DW.
Unstructured data can be stored in cloud-based object storage services like AWS S3, Azure Storage, or Google Object Storage.
This cloud lift & shift option may be ideal for organizations looking to move to the cloud without having to fundamentally change their data analytics architecture. However, many of the challenges listed earlier still exist with this model.
Cloud-Native Modern Data Stack
Simply migrating the data warehouse to the cloud is not sufficient to extract the full capabilities of modern cloud-based technologies. To attain full capabilities of modern cloud-based technologyes, the next stage is the modern cloud-native data stack whose key attributes are:
Fully managed cloud data warehouse (CDW)
Today’s CDW products are fully managed services, separation of compute and storage, supporting elastic scaling, high availability, end-to-end security, and requiring minimal setup and configuration. Since they unify the features of both the data lake and data warehouse, they are often called the “data lakehouse.”

Popular CDW products in this space are:
Cloud agnostic products from Snowflake, and DataBricks.
Offerings from cloud providers: AWS Redshift, Google BigQuery, and Azure Synapse.
Built-in operational workflow
The CDW products are built with end-to-end automation in mind, allowing users to set up new environments and pipelines without requiring engineers to write code or configure new instances.
Integration with cloud-native set of tools
The modern CDW integrates with a large number of tools for data extraction, loading and transformation which provides easy-to-use interfaces for non-technical users to set up their integration and transformation pipelines. Among the popular products in this space are:
Data Transformation tools like DBT.
Pipeline orchestration tools like Apache AirFlow, Flyte and others.
As data is ingested into the CDW, it moves through several stages in its lifecycle.

The raw data ingested from different data sources and formats, both stream and batch, is stored as-is in the Bronze or raw section, also called loading tables. Some minimal processing may be done before storing this raw data, like standardizing date formats, or removing personal information to comply with GDPR like regulations. This data often has long retention, enabling users to look at historical data for later analysis.
This raw data is then cleaned, normalized, and consolidated and stored in the next stage of the pipeline, the Silver or query tables. The kind of data transformations that can be done at this stage include, removing corrupt or incomplete, flattening tables, or converting JSON or XML into columnar formats. The result serves as the functional data warehouse, available for querying from reporting, BI, and analytical tools.
The Silver tables still contain a lot of data. It may be useful to generate aggregates from this data for faster reporting or machine learning. That is the purpose of the Gold or analytical stage. Most of the time the end users will access these tables for reporting.
This model provides both the benefits of the data lake, where all data is captured, and that of the data warehouse, which can provide clean, transformed data for query and analytics functions.
The modern cloud data stack not only simplifies this pipeline, but also provides additional capabilities around scalability, error recovery, and enforcement of data consistency and constraint.
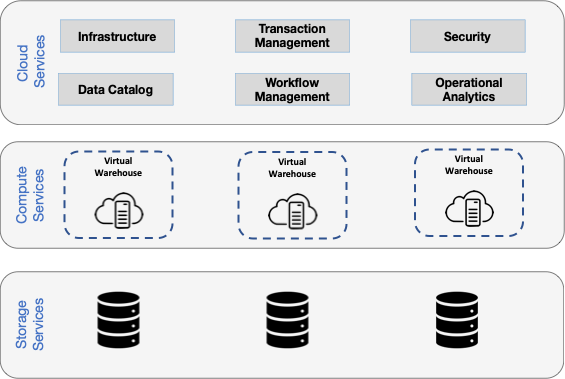
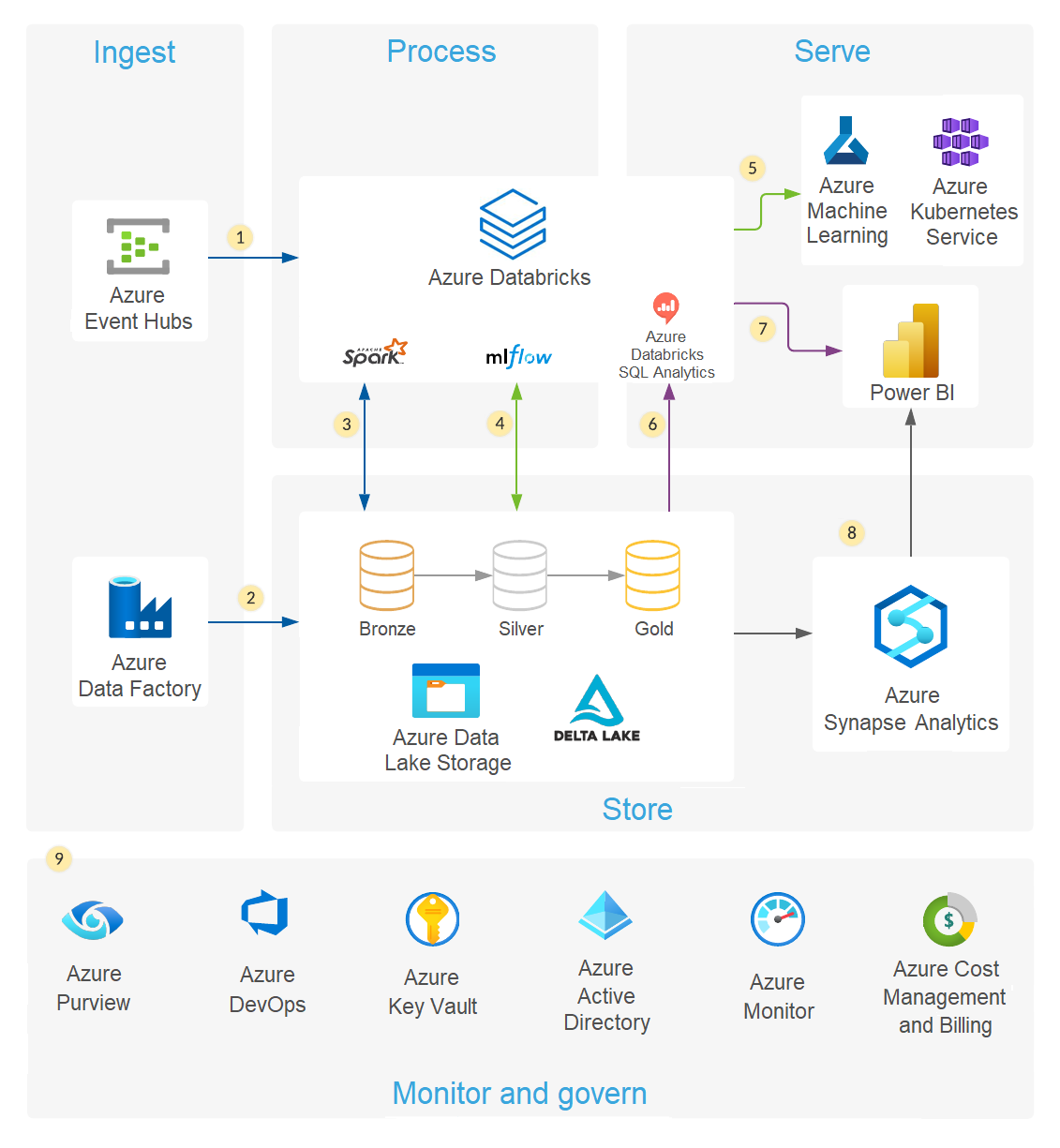
Here are two example architectures for a modern cloud data platform showing how these products can be deployed to multiple cloud providers, taking advantage of the various services offered by the cloud providers.
Here is a Snowflake reference architecture for a Customer 360 model built on multiple public clouds.

Here is a Databricks Delta Lake reference architecture for a modern data analytics platform built on Azure.
Among the major benefits of this modern data stack are:
Organizations, irrespective of their size and budget, can start experimenting with the modern cloud-based data stack immediately. It’s actually feasible to go to production quickly without massive investment and the hiring of infrastructure engineers.
Using cloud infrastructure, it is possible to scale up both compute and storage, constrained only by the cost. Also, each department can essentially have its own virtual warehouse, independently from the others, with its own size and cost footprint.
The modern data stack offers a common set of tools to do analytics on the data in the warehouse without requiring a large number of vertical-specific tools. It thus reduces the complexity of setting up multiple systems and delays introduced by data movement among them.
These cloud-based products offer high performance due to a several technology breakthroughs, like separation of compute and storage, the use of columnar storage and MPP (Massively Parallel Processing) database technology.
The modern data stack does not have any limitations on data formats, data protocols, or even connections with BI and analytical tools, allowing users to use the connect with services and tools of their preference. It has support for SQL analytics, and easily integrate with data science and AI/ML platforms.
All components of the modern data stack speak SQL, allowing for easy integrations and unlocking data access to a broad range of practitioners. It also makes it easy to share data with other data applications.
Modern software DevOps practices can be implemented in the data space. Known as “DataOps,” these practices include test-driven development, continuous verification, continuous deployment and integration, and monitoring.
All these products have non-functional capabilities like versioning, rollback, audit trails, support for reproducible ML experiments.
There are of course several challenges as well:
Data Governance is key to any data organization. Although there a few tools for data governance on the cloud in the areas of data cataloging and monitoring, this area is still maturing. Some of the products in this space are Alation, Collibra, and Talend Data Catalog.
Although organizations pay for compute only when needed, proper guardrails and governance need to be placed around cloud resource provisioning without which companies can be hit with unexpected costs.
The cloud introduces new architectural models and skilled practitioners may be harder to find.
Conclusion
The traditional on-prem data warehouse has served organizations well for many years by providing visibility into operational data critical for businesses to grow and thrive. However, this architecture tends to live in technical silos, introducing unnecessary friction into data-driven decision making.
The modern, cloud-based data warehouse can enable transformative connectivity between data and businesses, enabling data-driven decision making on a large scale, driving operational efficiency, improving customer experience, and creating new revenue streams.